In 2017, the paper "Attention is All You Need" introduced the Transformer architecture that now powers every major language model: GPT, Llama, Claude, and beyond. It was a foundational shift. And buried inside that architecture, it turns out, was both the problem and the answer to one of agentic AI's most dangerous vulnerabilities.
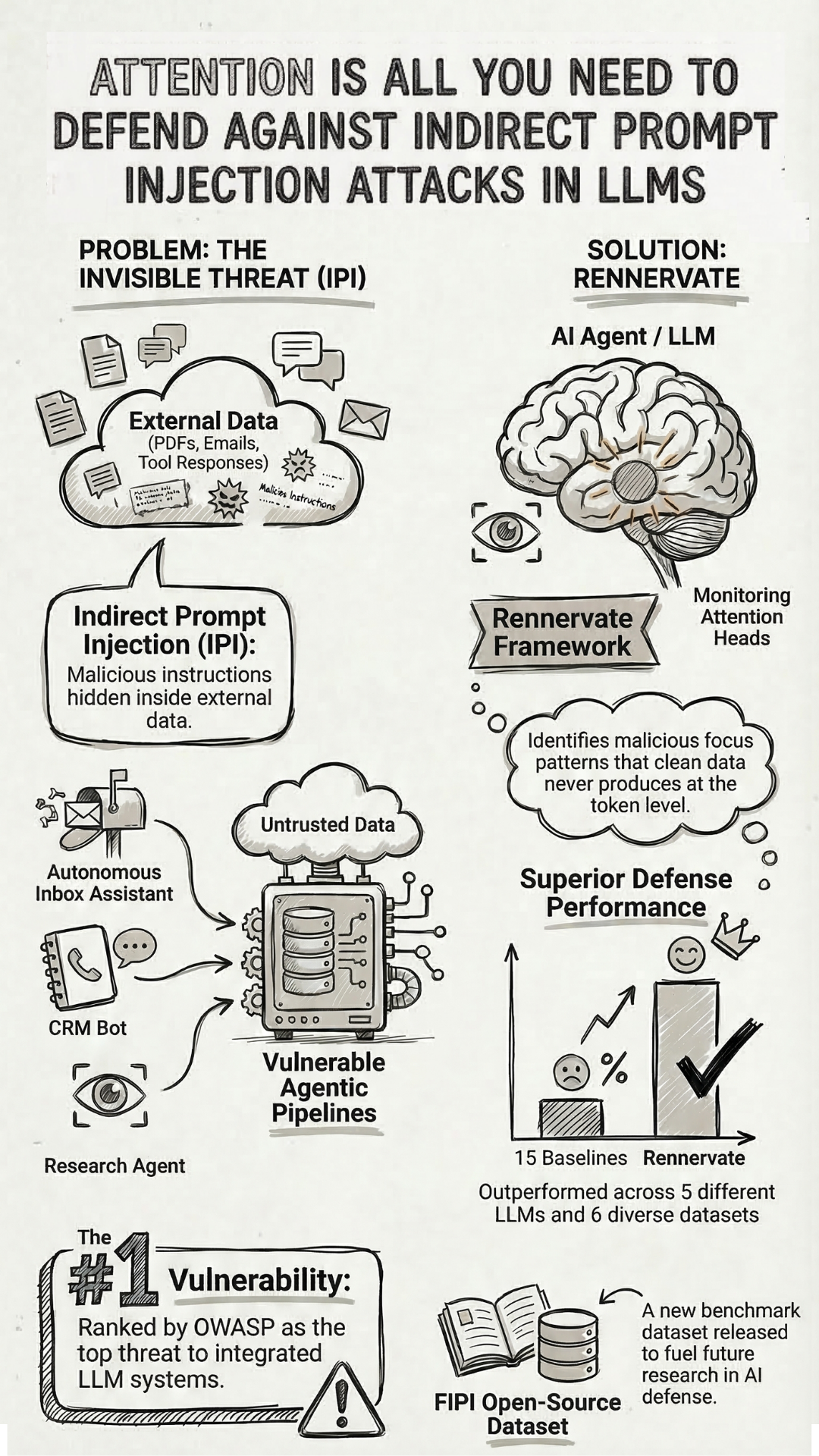
As AI moved from chatbots into production agents, the attack surface changed. Inbox assistants, CRM bots, research agents, enterprise pipelines chaining dozens of actions across tools and databases. These systems don't just respond to users. They read external content on users' behalf, and that's exactly where Indirect Prompt Injection enters.
Unlike direct jailbreaks, IPI doesn't require the attacker to interact with the user at all. Malicious instructions are hidden inside external data the model is supposed to read: a webpage, a PDF, an email, a database entry, a tool response. The model encounters the injection as part of its normal context and simply obeys. It leaks data, takes unauthorized actions, visits phishing sites, hijacks goals mid-task. One poisoned document in the pipeline, and the breach completes before anyone notices.
This is why OWASP ranked Indirect Prompt Injection as the number one vulnerability in its Top 10 for LLM Applications. Not theoretical. Not niche. The top of the list.
Why Existing Defenses Kept Failing
Prompt filters, output scanners, fine-tuning, auxiliary LLMs. None of them held consistently against sophisticated, adaptive attacks in real deployments. The injection lives inside the data the model must read to do its job. You can't instruct your way out of that, and you can't build a wall around information the system is designed to consume.
A team at Zhejiang University approached it differently. Instead of trying to detect malicious instructions by looking at their surface-level content, they asked a more fundamental question: what does an injection actually look like inside the model? Not what it says, but what the model does when it processes it.
The answer was in the attention heads. When a model processes injected tokens, it produces attention patterns that clean data simply doesn't generate. The model's internal response to manipulation leaves a fingerprint, and that fingerprint is consistent enough to detect and act on.
What RENNERVATE Does
At NDSS 2026, they presented RENNERVATE, a framework built on exactly this insight. It monitors attention heads directly during inference, identifies injected tokens at the individual token level, and surgically removes only the poisoned parts while leaving the legitimate content intact.
It requires no modifications to the underlying model, runs with under 0.8 million parameters, and is fast enough to operate in real deployments. Tested across five LLMs and six datasets, it outperformed all 15 baselines, and held up against attacks it had never encountered during training, including white-box adaptive adversaries with full gradient access who specifically optimized their attacks to bypass it.
They also released FIPI, an open-source dataset of 100,000 annotated injection instances, to support further research in this space.
Why This Matters for Agentic AI
Every AI web agent browsing on your behalf, every email assistant reading your inbox, every intelligent planner pulling from external sources to make decisions is exposed to this class of attack right now. The breach doesn't announce itself. It happens inside the pipeline, in the moment the model reads something it was never supposed to follow.
The signal was always in the attention heads. The same mechanism that made these models exploitable turns out to be what makes them defensible. For the number one vulnerability in agentic AI, that's a meaningful place to start.
Yinan Zhong, Qianhao Miao, Yanjiao Chen, Jiangyi Deng, Yushi Cheng, Wenyuan Xu. "Attention is All You Need to Defend Against Indirect Prompt Injection Attacks in LLMs." NDSS Symposium, 2026.